 |  |

 |

 |  |




 |  |  |
 |  |  |
 |  |
|
|  Main Main | |
| Architecture | |
 |  |  |
| | |
| |
|
| Tests | |
| Components | |
| Security | |
| Clustering | |
| | |
 |  |  |
![]()
Shaman is currently made of 3 different subsystems :
Spirit,
Insight,
and Legend.
Here is the big picture :
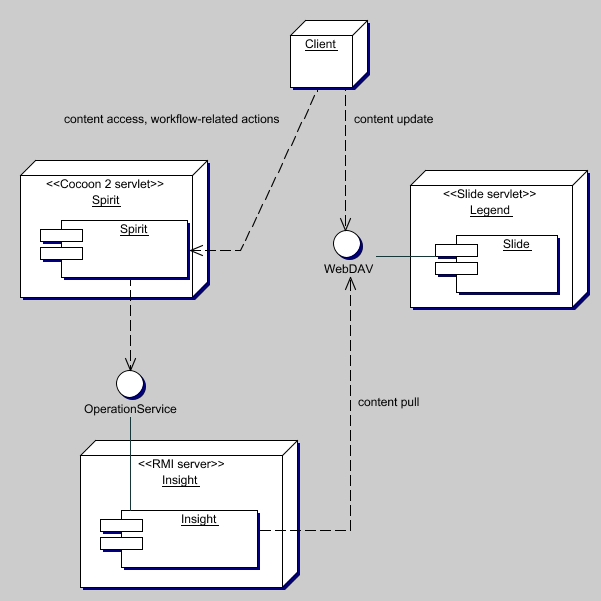
Spirit provides a customizable Web front-end, for both content access, and workflow features.
Spirit is a Cocoon application. It adds some components, configuration
files and scripts to the out-of-the-box Cocoon 2 distribution.
Spirit provides following features :
The Spirit subsystem bundled with Shaman intends to give an example of LCMS application, but users are strongly encouraged to invent their own and give us feedback then.
We intend to delegate User repository feature to a LDAP server (not shown on the diagram).
Insight
Insight is a proprietary database, whose role is to:
We had several good reasons for writing our own server:
java.net.URL
objects, allowing a remote content store.
The OperationService interface shown in the diagram below
represents a simple interface which accepts Operation
objects. This solves many problems of concurrency and parameter
passing.
The Insight server is designed to keep a rigid-but-generic data structure.
LegendLegend is the WebDAV repository, in which Authors store their "work-in-progress". We chose Apache Jakarta-Slide as WebDAV server implementation. There is not much to say about it, except that it never caused problem.
We intend to delegate User repository feature to a LDAP server (not shown on the diagram).